As of version 5.2.b.20161230, Audit Server includes the ability to directly monitor and audit PTP nodes, including
Domain Time (of course), as well as, appliance-type grandmasters, network switches, ptpd daemons on Linux and other platforms,
and most other PTP implementations.
IMPORTANT: This is an Experimental Feature.
It may or may not work as expected on your network. See the Requirements and Limitations sections below.
Usage
Use this list primarily for monitoring non-Windows PTP Masters and other PTP devices that cannot be audited directly via
the Domain Time II Nodes or
Domains and Workgroups lists in Manager.
Although Domain Time machines running PTP will also show up in the PTP Nodes list,
you should not audit them from here. You will get more accurate monitoring by
auditing Domain Time machines from the Domain Time II Nodes or
Domains and Workgroups lists and setting
Audit Server to collect synchronization logs from them.
See Synchronization Logs for details.
Linux machines running PTP can either be monitored and audited using PTP Monitor (from the PTP Nodes list) or by using ntpd or chronyd as
a reporting agent for time, in which case you can monitor and audit from the the NTP Nodes list. As described below, PTP monitoring
is more complex and subject to a number of limitations. If you are unable to use PTP Monitor against a Linux system for any reason, you should use the ntpd
reporting method instead. To use ntpd to monitor machines synchronizing by PTP, check your ntpd man pages on how to set ntpd to
run but not synchronize the clock, i.e. by adding lines like these to your ntp.conf file:
server 127.0.1.0
fudge 127.0.1.0 stratum 2
In this configuration, PTP will set the Linux system clock and ntpd will merely report that time. You can then add the Linux machines to the
NTP Nodes list for auditing.
Considerations
PTP is primarily a time-distribution methodology, and monitoring of non-master nodes is not always possible.
Support for management messages is optional in the specifications, and some manufacturers may leave it out entirely, or implement
only portions of the specification. You may use the PTPCheck
utility to test the capability of any PTP node to respond to management messages.
PTP monitoring uses a mixture of multicast and unicast to gather data. Contact with each node is inherently
unreliable, and success will depend on both your network configuration and the capabilities of the node being monitored.
PTP Monitoring is quite network-intensive, with large amounts of multicast traffic. Make every effort to limit the scope of
your scans using the Hops limits and Domains to Monitor section of the configuration. The number of machines that can be
effectively monitored depends largely on your network capabilities to handle this extra traffic. You can monitor many more systems
using the direct monitoring methods for Windows (Domain Time Nodes) and Linux (NTP Nodes) methods mentioned above.
PTP monitoring uses many more message types and functions than normal PTP synchronization traffic. Many PTP-capable
switches and routers have had bugs that have prevented these messages from being propagated correctly to all machines. Be sure to
update your switches and routers to the latest firmware. If you are having problems seeing machines using PTP Monitor,
try swapping out the PTP-aware device with a standard nework switch and see if that resolves the issue. If so, you'll need
to obtain a fix from the hardware vendor.
Requirements
You must install or upgrade to Audit Server version 5.2.b.20161215 or later (Server, Manager, and Audit Server must be installed
and running the same version). You must then enable PTP Monitor from Manager's menu (Audit Server -> PTP Monitor -> Enable)
or by right-clicking the PTP Nodes label in Manager tree and choosing Configure... from the context menu.
Only IEEE1588-2008/2019 (PTPv2.0 & v2.1) nodes may be monitored. PTPv1 messages are not supported, and PVPv3 has yet to be released.
For the remainder of this discussion, "the standard" refers to IEEE1588-2008.
PTP Monitor uses Layer 3 (UDP) only. It cannot detect or interact with nodes that only use lower-level transports.
Nodes to be monitored must be visible on the wire from the machine running PTP Monitor. If your network is segregated to prevent
multicast traffic from crossing boundaries, then PTP Monitor will be limited to those nodes visible from its own location.
You may run multiple instances of PTP Monitor on different networks to overcome this limitation.
Generally, nodes being monitored must respond to both multicast and unicast PTP management messages, as defined in the standard.
The exception is Masters may be partially identified even without management messages, via their Announce and Sync messages.
As of version 5.2.b.20170922, PTP Monitor may be configured to use multicast management messages for node discovery and also
for delay measurement against discovered Masters. Note, this improves compatibility at a cost of more network traffic.
You may use the PTPCheck
utility to test the capability of any PTP node to respond to management messages.
PTP Monitor uses multicast to discover nodes and to collect information that all nodes have in common.
By default, PTP Monitor then uses unicast directly to each node to collect further information and monitor changes. As of
v5.2.b.20170922, all discovery may be configured to be via multicast instead of unicast.
PTP Monitor sends its multicast discovery packets to each multicast-capable interface on the machine hosting PTP Monitor.
If the interfaces change dynamically (for example, connecting a VPN, changing an IP address, enabling/disabling an adapter,
or plugging/unplugging a cable), PTP Monitor will dynamically reconfigure itself to use only the "up" interfaces. It will
also attempt to rejoin the IEEE 1588-specified multicast groups as interfaces come and go. This behavior means that PTP
Monitor will likely be able to "see" all of the nodes reachable from the host machine; however, you must still configure
routers, switches, or firewalls to allow the traffic as needed.
Domain Time includes a very useful tool for testing to be sure you are able to receive management messages.
Use the PTPCheck utility to verify that
management messages are passing across your subnet boundaries and through your switches, routers, and boundary clocks correctly.
PTP Monitor sends its unicast followups according to its host's routing table. Unlike multicasts, unicast routing is managed
by the operating system. If your network consists of VPN-linked subnets, you may need to adjust the routing table for each
subnet to ensure the proper gateway is used to reach each node. (If you can "ping" a node from the command line, the
routing table is correct.) It does not make sense to send duplicate unicasts over each interface, since in most cases,
the operating system will ensure the correct gateway is selected, and the redundant packets would either be dropped
or report network-unreachable errors.
PTP Monitor uses a default IPv4 TTL (and IPv6 Hopcount) of 1 for multicasts. You may adjust this value in order to
monitor nodes outside of your local LAN. However, you may also need to adjust the TTL/Hopcount on the monitored nodes in
order for the replies to reach PTP Monitor. PTPd uses a default TTL of 64 for everything except Peer-to-Peer messages.
You may adjust this by editing /etc/ptpd2.conf and adding (or editing) the line
ptpengine:multicast_ttl=n where n is the
TTL you want, then restarting the PTPd daemon. (This information is true for the official PTPd version 2.3.1;
ports, customized versions, or newer versions may work differently.) Domain Time allows you to adjust the IPv4
TTL and IPv6 Hopcount from the Control Panel applet's Network/Broadcasts and Multicasts page. Changes take effect
immediately. We recommend you set the TTL/Hopcount to the lowest number possible for your network requirements.
Note: PTP Monitor cannot detect or interact with nodes using the Telecom Profile (negotiated unicast). Such nodes are forbidden by
the standard from joining multicast groups. Even if they could respond to unicast queries, there is no way to discover a node's
PortIdentity when it uses the Telecom Profile.
Due to the amount of network traffic generated by PTP, the practical number of PTP Nodes that may be monitored from a
single Audit Server is lower than when monitoring using other protocols (such as DT2 or NTP). The exact number is
difficult to quantify, since it depends on your particular network design and the capabilities of the network devices and host machine
to handle large numbers of UDP packets. PTP time accuracy and monitoring will suffer dramatically from delayed or dropped UDP packets,
so keep a close eye on your network metrics to watch for high/spiky latencies or packet queueing. For this reason, Audit Server has
a built-in limitation on the number of PTP nodes it will track. By default, the limit is 2000 nodes. Please contact support if your
situation warrants a higher limit.
Although you may operate PTP Monitor with Manager set to use DT2 or NTP sources for its reference clock,
it is highly recommended to have the Domain Time Server on your PTP Monitor machine set to be a PTP slave of your best local hardware PTP
grandmaster. Domain Time Server would then be steering the local clock to precisely match the master. The correct reference clock
setting for Manager would then be to use the local machine's clock.
Basic Operation
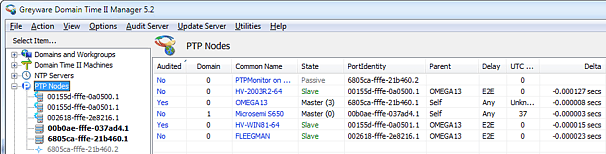
You may view the active status of your PTP network using the PTP Nodes section of
Domain Time II Manager.
Displayed nodes may be selected to be included in scheduled Domain Time II Audit Server audit list, and
will therefore raise the same alerts and be included in the same reports during audit scans as other audited protocols such as
DT2 or NTP. PTP nodes may be auto-added to the Audit List using Audit List Management.
Tracking via PTP is provided in addition to monitoring by other protocols. For example, a PTP appliance that also serves NTP may appear
in both the NTP Nodes list and in the PTP Nodes list. A Domain Time Server acting as a PTP Master may
appear in those two lists plus the Domain Time II Nodes list. Each protocol has its own advantages and disadvantages,
and it may occasionally be useful to monitor multi-protocol nodes by more than one protocol.
For example, if you have a Domain Time Server acting as a PTP master, auditing it as a PTP Node will show you the quality of time
being served by the master, whereas the regular Domain Time II auditing will show you how well that machine is tracking its own sources.
However, in general you should not audit machines on both the PTP Nodes list and from the Domain Time II Nodes list. Use the Domain
Time II method if available.
PTP Monitor can monitor multiple PTP domains. If you have more than one logical PTP network (a "domain") sharing the same wire,
nodes will discard messages from any domain except their own. However, PTP Monitor can see them all, and track both
Masters and Slaves in multiple domains. You may limit the domains being monitored from Manager's configuration pages for
PTP Monitor. The configuration dialog page lets you specify individual domain numbers, ranges, or both.
PTP Monitor can collect synchronization logs (drift files) from
audited PTP nodes (masters and slaves). These two new drift files types are separate from the drift files collected by other protocols
and are described in detail on the Synchronization
Logs section of the Audit Data documentation.
Notes:
If a node in the PTP Nodes list is a Domain Time machine, you may remote-control it by double-clicking either the portIdentity
or the IP address, or by right-clicking anywhere on the line and choosing Control Panel from the context menu.
If a node is running the Linux domtimed daemon, double-clicking will show the statistics. Otherwise, remote control is not available
from the PTP Nodes list.
The Audit Server Real-Time Alert feature
is not provided for PTP Nodes. However, Domain Time II Servers or Clients can provide that functionality independently of PTP Monitor.
The auditing of PTP Nodes is a separate function from other types Audit Server auditing. The "Audited"
setting's column for PTP Monitor is independent of the "Audited" settings
on the Domains & Workgroups, NTP Nodes, Domain Time Nodes, or Real-Time Alerts displays.
Enabling/Disabling auditing on the PTP Monitor display will not change the audit settings on the other pages, and vice versa.
Configuration
PTP Monitor is configured using the PTP Monitor Configuration dialog. You launch the dialog from either Manager's menu (Audit Server -> PTP Monitor -> Configure)
or by right-clicking the PTP Nodes label in Manager tree and choosing Configure... from the context menu.
Monitor Enabled IPv4 Enabled (required) IPv6 Enabled (optional)
PTP Monitor is off by default. When PTP Monitor is enabled, IPv4 operation is always active.
Do not enable IPv6 unless it is required. Otherwise you will be duplicating multicast traffic needlessly.
Keep a node online if it responds to some, but not all, management messages
By default, PTP Monitor will show nodes as online if they have responded to all management messages during the previous discovery sweep.
However, some PTP nodes do not reply to all management messages (see Limitations) and would therefore
show as offline. Checking this box ensures that nodes responding with partial information will be marked as online.
Operating Domain: Range 0-127, default 0
Allows you to specify the base PTP Domain that PTP Monitor operates on by default.
Boundary Hops: Range 1-64, default 1
Indicates the number of PTP boundaries to cross when discovering machines. Increase this value only if you are on a network segment
connected to a PTP Boundary Clock and you wish to discover PTP devices on the other side of the Boundary Clock (such as the actual top-level Grandmaster).
Otherwise PTP Monitor will only discover the Boundary Clock on the local segment. Note you may also need to increase the
Multicast Hopes/TTL value in order to hear multicasts from the remote subnet.
Multicast Hops/TTL: Range 1-64, default 1
Indicates the number of router hops a PTP Monitor multicast packet will traverse. This value is also known as multicast TTL (Time To Live).
You must set this number large enough to account for all of the router/switch transitions a packet must cross in order to reach your
entire network. Note that this value is independent of the Network Discovery multicast TTL
value used for machine discovery by Domain Time Manager itself.
Domains to Monitor: Comma-delimited list of domains, or ranges
This value specifies on which PTP Domains you want PTP Monitor to attempt to discover nodes. PTP Monitor can monitor all possible
PTP domains (0-127) simultaneously. You may limit the scope in order to reduce network traffic, or in order to segregate monitoring
functions among multiple PTP Monitors.
Set this value to include only the actual PTP domain numbers in use on your network. Discovery sweeps are sent to each specified
domain, and can generate a significant amount of unneeded traffic and take a significant amount of time if unused PTP domains are
included. You may specify individual domains and/or a range of domains.
Sweep at audit time, or when refreshed from Manager Sweep at a regular interval in the background Interval: seconds; range 5-86400, default 30
Use these radio buttons to select the type and rate of discovery sweeps. As mentioned above, discovery sweeps can
generate a significant amount of multicast traffic. If you are monitoring a large number of PTP Nodes, you may want to only discover
nodes on-demand (or when running an Audit), or use a relatively infrequent automatic scan interval.
As of version 5.2.b.20170922 you may select whether follow-ups are sent via unicast or multicast using the
Sweep follow-ups radio buttons. Using multicasts creates a significant amount of extra traffic to remote subnets and should only be used if you have devices that
do not support unicast management messages.
Master Check Interval: seconds; range 0-65535, default 2 (zero = disabled)
Master clocks are discovered by their announcements independently of discovery scans. PTP Monitor regularly measures the mean path delay
between the Master and the PTP Monitor machine to assure accurate time delta information. This selection allows you to specify the
number of seconds between delay measurements.
As of version 5.2.b.20170922 you may select whether delay measurement is done using unicast (hybrid mode) or multicast-only using the
radio buttons. Using multicasts creates a significant amount of extra traffic to remote subnets and should only be used if you have devices that
do not support hybrid mode.
Assume Grandmasters with stepsRemoved of 0 have zero deltas Measure all Grandmasters to discover deltas (estimate ± 150µs)
You may choose to accept a grandmaster at face value if it claims zero stepsRemoved from a primary time source such as GPS/GNSS.
If "Assume Grandmasters with stepsRemoved of 0 have zero deltas" is selected, each master's delta will not be measured against the local clock,
and will show as 0 µs. This is the correct behavior according to IEEE1588-2008 Table 13.
The other option, "Measure all Grandmasters to discover deltas (estimate ±150µs)," tells PTP Monitor to observe the Sync/Follow-up messages and estimate each master's delta by comparing
it against the local clock, accounting for measured E2E or P2P latency. The computation of the master's delta is only an estimate because
PTP Monitor only observes packets and does not attempt to syntonize or synchronize with any particular master. It may be following
multiple masters in several domains simultaneously. Previous versions of Domain Time Audit Server always attempted to measure the deltas,
leading to some confusion among admins who expected a grandmaster to be at least as accurate as a slave and did not realize that master
deltas were estimates. The new default is to assume grandmasters are telling the truth, provided they report stepsRemoved as zero.
You may regain the former behavior by choosing the second radio button. Note that masters that claim stepsRemoved of non-zero are always
measured against the local clock, yielding estimated deltas.
Auto Drop Period: days; range 1-3650
Specifies how long unresponsive PTP nodes remain on the PTP Nodes list. Stale PTP nodes in the list result in extra discovery sweep traffic/timeout delay.
Use this value to help keep your nodes list current.
Discovery Sweeps
Discovering PTP Nodes on a network is a complex process. Although some information can be gathered passively by listening to PTP
traffic, it's necessary to periodically send queries of various sorts to acquire all available data. These exploratory probes
are known as Discovery Sweeps.
PTP Monitor uses both multicast and unicast to obtain state information about nodes. General discovery is done by periodic
multicasts; follow-up queries are sent directly to each node using unicast. (As of v5.2.b.20170922, you may send follow-ups using
multicast only. See the Configuration section above.) Most hardware grandmasters, PTPd as of version 2.3, and
all Domain Time nodes support mixed message types. This is very similar to the "hybrid" mode used by slaves; see the
Enterprise Profile section of the PTP Profiles
documentation for more information.
PTP Monitor does not need to sweep the network in order to discover master nodes; an overheard Announce and subsequent Syncs/Sync Follow-ups are sufficient.
PTPd and other software slave nodes can only be monitored effectively by sweeping the network. If you only require the information
as part of an audit, you may let the commanded sweep from Audit Server collect the information. If you require an up-to-date display
on Manager, you will need to use F5 Refresh or enable periodic background sweeps.
Domain Time nodes announce state changes and significant events, so sweep is not required for the current status of Domain Time
slaves or masters. If all of your PTP client software is running Domain Time, you may disable periodic sweeps altogether.
Note that Audit Server will perform a sweep at the beginning of an audit, or when you first open Manager (or hit F5 on Manager's
PTP Nodes display). This behavior helps ensure the information from each node is as recent as possible.
Limitations
Although PTP Monitor is able to auto-discover most PTP nodes on a network, there are circumstances that may prevent machines from
being detected and/or fully identified.
Management Messages
As noted in the Requirements section, only nodes that support both multicast and unicast management
messages may be monitored (with the exception of Master nodes using multicast Announces and Syncs).
PTP Monitor uses the information from the Clock Description management query to fill in the fields for device name,
hard/firm/software versions, and other identifying information. You may edit the "Common Name" and "DNS Name" fields.
Please note that all but a very few fields of the Clock Description response are optional, and that many
implementations either do not support the message at all, or support only a subset of the information.
For example, all PTPd nodes report a device name of "PTPDv2" and a software version number, but no other identifying information.
Management message handling is optional per the standard. Most appliance-type grandmasters, ptpd as of version 2.3,
and Domain Time, accept and reply to management queries. However, nodes are not required to handle management
messages at all; even those that support management messages may only support a limited subset of message types.
PTP Monitor can detect and monitor nodes acting in the Master state, whether or not they reply to management messages.
Note: if the Master being monitored does not support management messages, some of PTP Monitor's information will be incomplete.
PTP Monitor tracks masters by listening for multicast Announce and Sync messages, and calculating the difference between its
own clock and the advertised time. In this sense, PTP Monitor acts like another Slave; that is, delay information is
collected periodically, and the timestamps in the Sync messages are used to determine
the offset of the master from the PTP Monitor machine. on the network.
Note that this is not as precise of a measurement as a true slave could derive, because the machine is not performing
corrections based on the incoming timestamps. Master node offsets are recalculated upon the receipt of each Sync/Sync
Follow-up message.
If the Master does not support E2E or P2P unicast delay requests, then you should change to using multicast for delay measurement.
Since PTP Monitor is not actually a Slave (does not try to match frequencies), the deltas
reported by PTP Monitor will be somewhat higher than those reported by Domain Time Server running on the same machine.
This is expected behavior, and is essential to PTP Monitor's functioning because PTP Monitor can track multiple masters at the same time.
Management messages, whether unicast or multicast, are always directed to port 320.
Unicast replies to management messages may be sent either to the source port of the request,
or to port 320 (this is implementation-dependent). For this reason, PTP Monitor always sends its
requests from port 320, to ensure that nodes from different manufacturers will be able to reply
no matter how they interpret the standard.
Offset measurement
The PTP standard is primarily a specification for time distribution; in particular, the standard specifies how Slaves should
determine an acceptable Master, and how they should interact with that Master, and forbids Slaves from responding to
Master-only messages.
For example, Slaves are forbidden from responding to delay requests, so the network distance
between PTP Monitor and a Slave cannot be measured directly. Slaves are also forbidden from placing Announces or Syncs
on the wire, so the offset between PTP Monitor and a Slave cannot be measured directly, either. Through management messages,
Slaves can report their own measurements of their offset and distance from the Master, and which Master they are following.
PTP synchronization data for slave nodes is collected from the slave's own measurement of its offset from its master.
The slave's information is collected only when a discovery sweep occurs. IEEE 1588-2008 specifies only the type of data
to be returned, not its source; this means that the values provided are implementation-dependent. Some nodes may return the
most-recently calculated offset prior to correcting for it, others may return the offset after the most recent correction,
while still others may supply filtered data. Further, IEEE 1588 does not specify what values should be returned when a
node was previously a slave but has lost its master, nor what masters should declare if they are not using a direct
connection to a GPS timesource. Therefore, although the information may be present and valid, PTP Monitor will only
report on it if the node is currently a slave.
Masters are required by the standard to set their own offset and delay values to zero. Slaves are required to report their
Master's time source as their own. If a Master happens to use NTP to obtain its own time, it should report its time source
as NTP, but will still report its offset and delay as zero. If a Slave uses PTP to obtain time from that master, it will
also show its time source as NTP. The Slave will report its offset and delay from the Master, but not from the Master's
source, because the standard has no way to represent a master's offset or delay. Likewise, if the Master is an appliance
using GPS, it and all of its Slaves will report a time source of GPS, even though the slaves are using PTP.
PTP Monitor directly measures Masters by processing its Announces and Syncs. It does not attempt to measure Slaves, because the
standard does not allow it. For Slaves, the reported offset and delay are accepted at face value.
The standard leaves clock steering as an implementation detail. Thus, there is no way to distinguish between a Slave that
has measured its offset and delay but not yet compensated for it, from a Slave that reports its most recent actual
synchronization. Each manufacturer is free to report whatever set of values it feels appropriate (including none at
all if it fails to respond to management messages).
Time Since Last Set
NTP and DT2 report their time sources, and the time elapsed since they checked. This information is available without examining
logs, by virtue of the data contained in the time packets exchanged.
The PTP standard does not define this property, and there is no way of measuring it. A Master is presumed to be always correct
at all times, and the clock steering mechanism used by Slaves is implementation-dependent. Therefore, any node that claims to
be either Master or Slave is presumed to be have set its clock if it responds at all. The Slave may, in fact, be in the middle
of a two-hour slew to correct the offset, and it may report either the offset from when it discovered the need to slew,
the current offset as the slew occurs, or the expected offset after the slew has completed. It will not report when it discovered
the offset or whether a correction has been made.
A node that remains online (responding to management messages), but that reports its state as something other than Master or Slave,
allows PTP Monitor to calculate the time since last set as long as the node has been a Master or Slave in the past. For example,
if a Slave loses its Master while being monitored and changes from Slave to Listening, PTP Monitor will know how much time has
passed since the clock was last a Slave. But if a node remains in the Listening or Passive state, or fails to respond to
management messages (perhaps because it's now offline), PTP Monitor has no data, and reports will show "Unknown" as the time
since last set.
Other Information
portIdentity
All PTP nodes are required to have a unique portIdentity. The portIdentity is formed from a 64-bit value called the clockIdentity,
plus a port number. The clockIdentity is normally formed from the MAC address of the primary adapter, with 0xFFFE inserted in the
middle to make a 6-byte field into an 8-byte field. clockIdentity may also use the manufacturer's 3-byte OUI plus a
guaranteed-unique remaining 5-byte value.
PTP Nodes use the portIdentity to distinguish among Masters. When a Slave sends a delay request to its Master, it includes its own
portIdentity in the request, and the Master sets this as the target for the reply. This scheme allows either multicast or unicast
for delay measurement between Slaves and their Masters, since a Slave can pick out its own reply.
Management messages, whether multicast or unicast, must include the target portIdentity. PTP nodes cannot be addressed by their
IP address or DNS name alone. PTP Monitor uses a special kind of multicast management message addressed to "all clock, all ports"
to gather the portIdentities of the various nodes. (There is no corresponding "all domains" message type, although v3, when released,
will likely support it. Domain Time already does. At the moment, the "all clocks, all ports" messages must be duplicated for each
monitored domain.) After learning a node's portIdentity, PTP Monitor can then direct unicast requests for further information
directly to the node, using the IP address from which it responded. This combination of multicast and unicast allows PTP Monitor
to track nodes even if they use DHCP and change IP addresses.
Hardware appliances typically have the portIdentity "baked in" at the moment of manufacture, usually using the manufacturer's OUI.
A hardware appliance should never change its portIdentity under normal circumstances, although each Ethernet port on the appliance
may have its own portIdentity (usually the same clockIdentity with a different port number).
PTP-aware routers and switches, acting as boundary clocks, typically have a baked-in clockIdentity shared by all ports, and a port
number corresponding to each Ethernet port. These values normally never change.
Software nodes, such as ptpd, follow the standard exactly, using the MAC address of the primary adapter. This is usually sufficient
to ensure that, from boot to boot, the portIdentity will be unique and constant. However, the concept of "primary adapter" is
OS-dependent, and may change either after a reboot or even while running. Most implementations will not change portIdentites
while running, even if moved to a different adapter (say, for instance, a live migration from one virtual host to another, or a
live change of active adapters). At reboot, however, the node will discover a different MAC address, and begin participating with
a new portIdentity.
Domain Time nodes maintain a persistent portIdentity from the moment of first mobilization. If a duplicate node is discovered on the
network, Domain Time will switch to the Faulty state and report the duplicate's IP address in the log file. Otherwise, Domain Time
will continue using the same portIdentity, even if NICs are swapped or the machine is live-migrated to a new host. Domain Time
allows an admin to change the clockIdentity if a conflict is discovered.
Since the only uniquifier for PTP is the portIdentity, historical records are subject to contamination if nodes end up swapping
portIdentities. This could happen if you swap NICs between two ptpd nodes, of if you migrate ptpd nodes to different hosts and then
reboot them. The standard's only requirement is that all portIdentities must be unique during the operation of the time distribution,
as seen from the Master's perspective.
If a node merely changes its portIdentity to a different (but unique) value, PTP Monitor will show the old node offline, and
begin tracking the new one. Since synchronization logs are kept by the portIdentity, you may end up with a new log starting for
the same node, or (worst case), data from one node being appended to data from another node that formerly used that portIdentity.
If you clone installations, you may end up with multiple nodes having the same portIdentity. The behavior of PTP under these
circumstances is undefined. The nodes will probably not be able to synchronize with the Master, and PTP Monitor will not be able
to tell them apart. Domain Time checks for this condition at each startup, but detecting duplicates depends on the proper functioning
of multicast management messages among non-Master nodes.